

Background
As mobile applications become increasingly prevalent, malicious software is also becoming more complex and covert. This report focuses on a malicious Android sample submitted by ReBensk to incinerator.cloud.
Basic Information
-
Sample Hashes:
- MD5: 2f371969faf2dc239206e81d00c579ff
- SHA-256: b3561bf581721c84fd92501e2d0886b284e8fa8e7dc193e41ab300a063dfe5f3
Among multiple malicious samples submitted to incinerator.cloud by ReBensk, we pay special attention to a custom-modified APK file, hereinafter referred to as "Sample b356." This sample employs unique obfuscation and evasion techniques, which make it resistant to conventional decompression tools. Through specialized remediation, we were able to bypass this limitation and analyze the sample further.
Analysis Process
Structural Corruption in AndroidManifest.xml
Reason for Failure in Initial Analysis
Using the 010 Editor, we attempted to analyze the remediated AndroidManifest.xml binary file from Sample b356 with the AndroidResource template. This initial attempt failed, revealing issues beginning at pos:0 of the file.
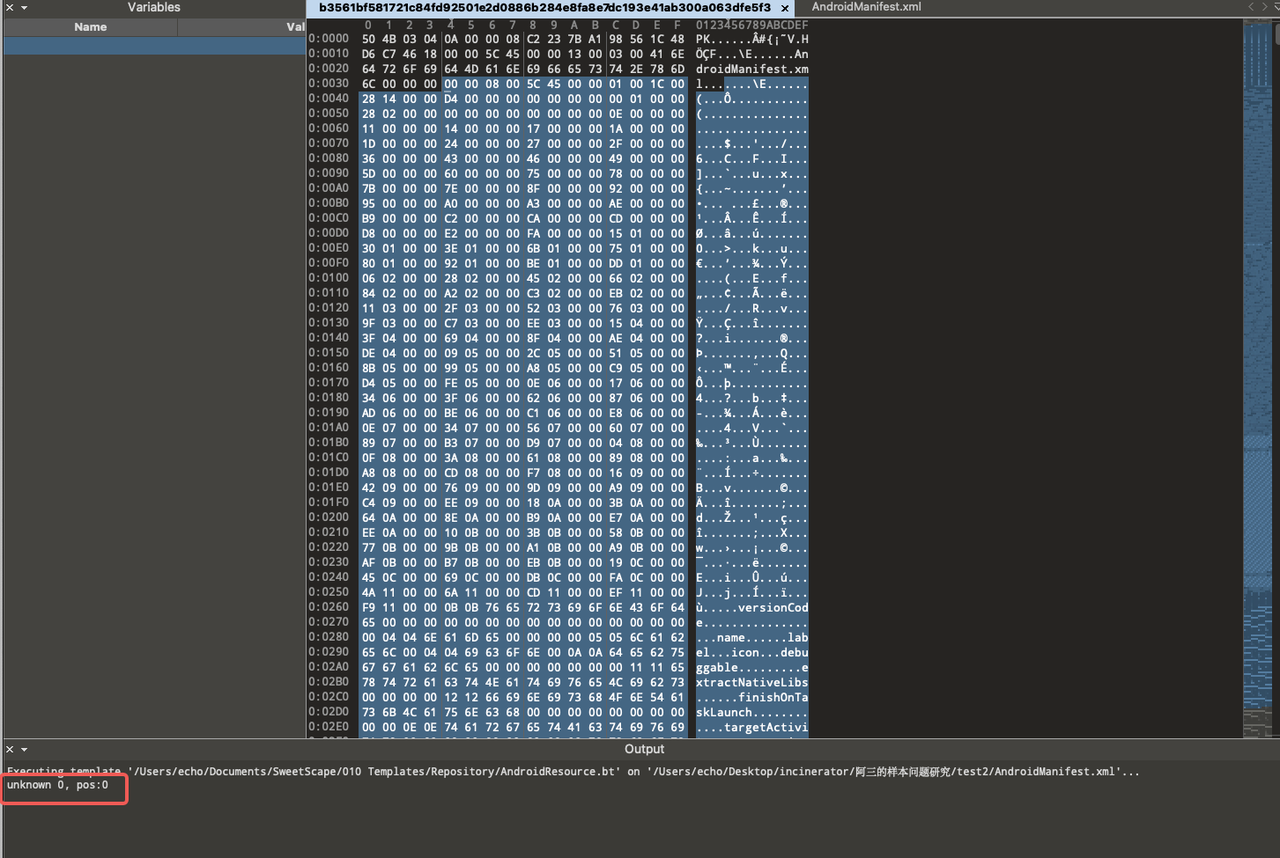
By comparing this with a standard AndroidManifest.xml binary file, we noticed a discrepancy right at the first byte.
Resource Type Definitions:
enum {
RES_NULL_TYPE = 0x0000,
RES_STRING_POOL_TYPE = 0x0001,
RES_TABLE_TYPE = 0x0002,
RES_XML_TYPE = 0x0003, // Chunk types in
RES_XML_TYPE RES_XML_FIRST_CHUNK_TYPE = 0x0100,
RES_XML_START_NAMESPACE_TYPE= 0x0100,
RES_XML_END_NAMESPACE_TYPE = 0x0101,
RES_XML_START_ELEMENT_TYPE = 0x0102,
RES_XML_END_ELEMENT_TYPE = 0x0103,
RES_XML_CDATA_TYPE = 0x0104,
RES_XML_LAST_CHUNK_TYPE = 0x017f, // This contains a uint32_t array mapping RES_XML_RESOURCE_MAP_TYPE = 0x0180, // Chunk types in RES_TABLE_TYPE RES_TABLE_PACKAGE_TYPE = 0x0200,
RES_TABLE_TYPE_TYPE = 0x0201, RES_TABLE_TYPE_SPEC_TYPE = 0x0202
};
According to Android specifications, this byte should typically be 0x03, which is not the case in Sample b356.
Why android can parse?
Locating the source code for Android parsing,
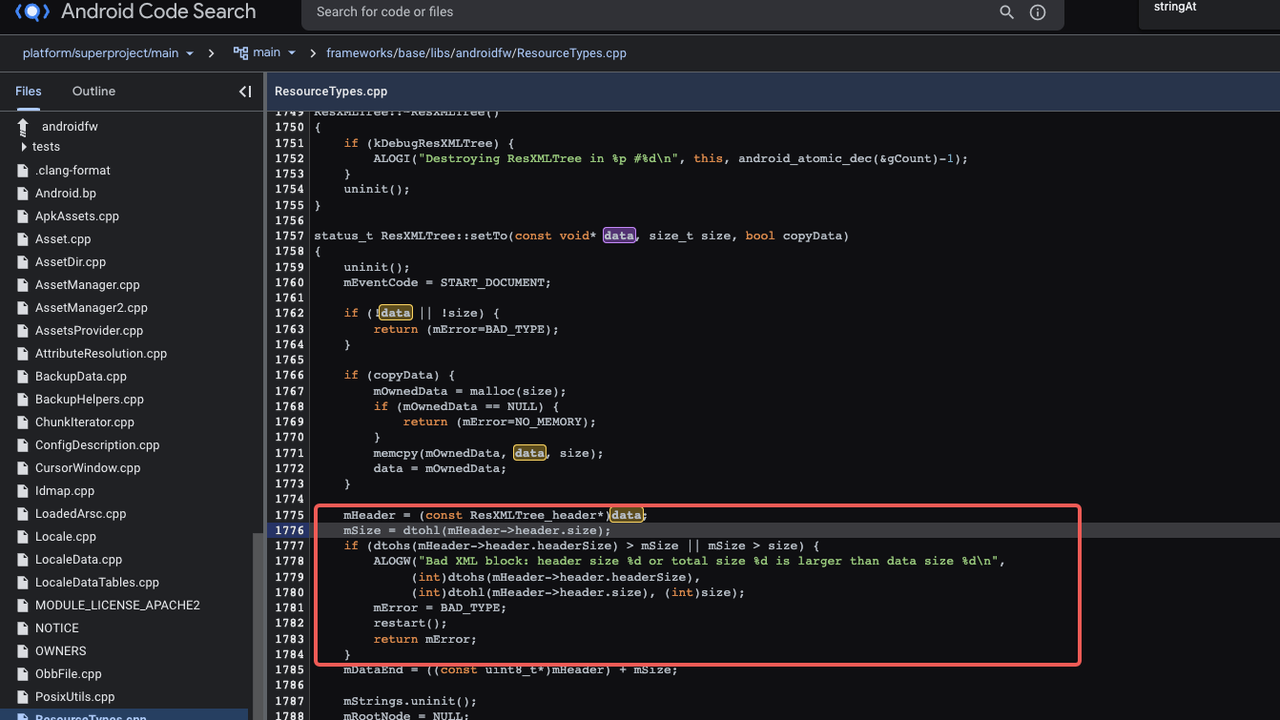
This is the point where the parsing of the Androidmanifest.xml binary initiates. Upon examining the source code, it becomes apparent that there is no validation of the first two bytes as 0x0003. Instead, the legality of the headerSize is the sole aspect subjected to verification. Consequently, even after altering the file type in sample b356, Android retains its capability to accurately parse the file.
Modification Suggestions
Static analysis tool fix suggestion: keep the same parsing process with Android system, no file type verification here.
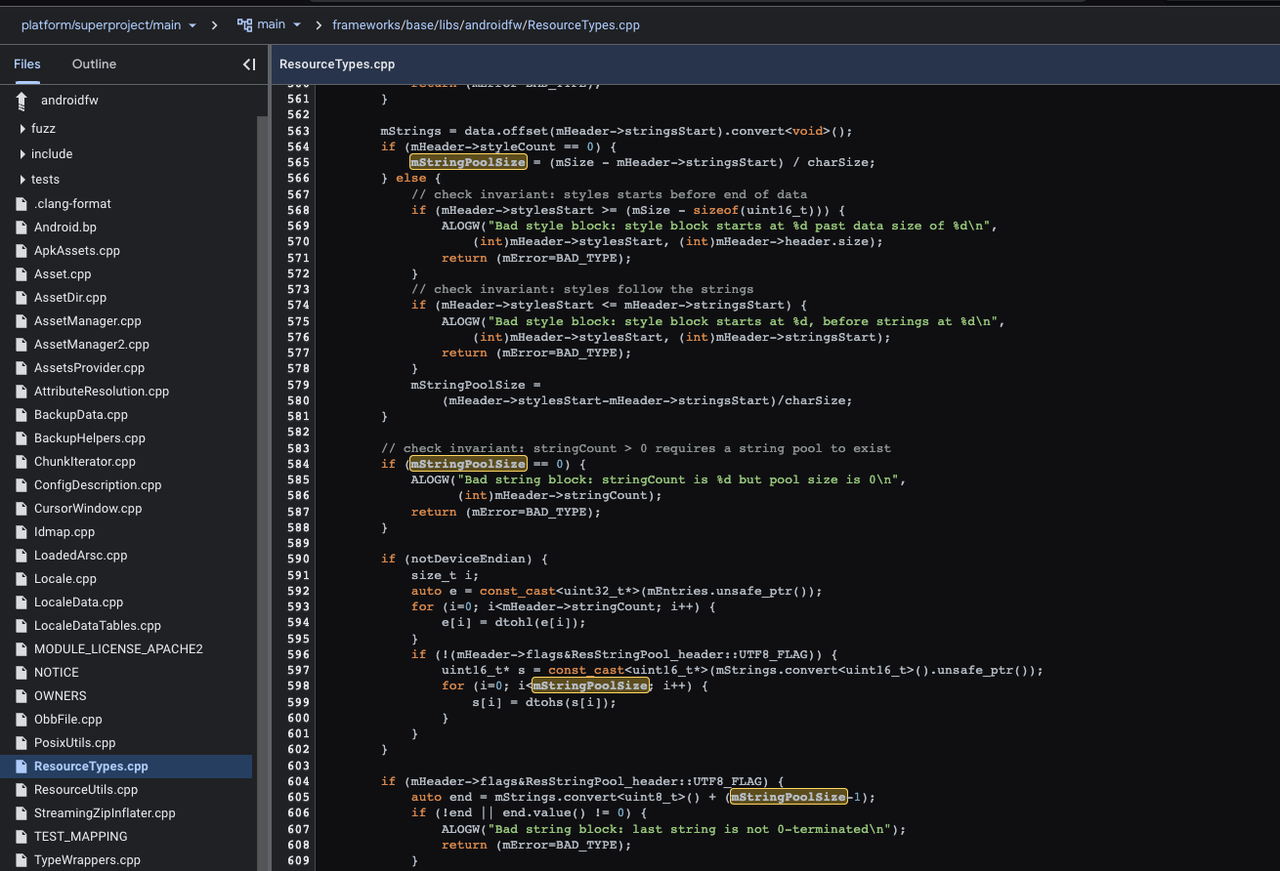
StringPoolSize Modification
Data Anomaly Analysis
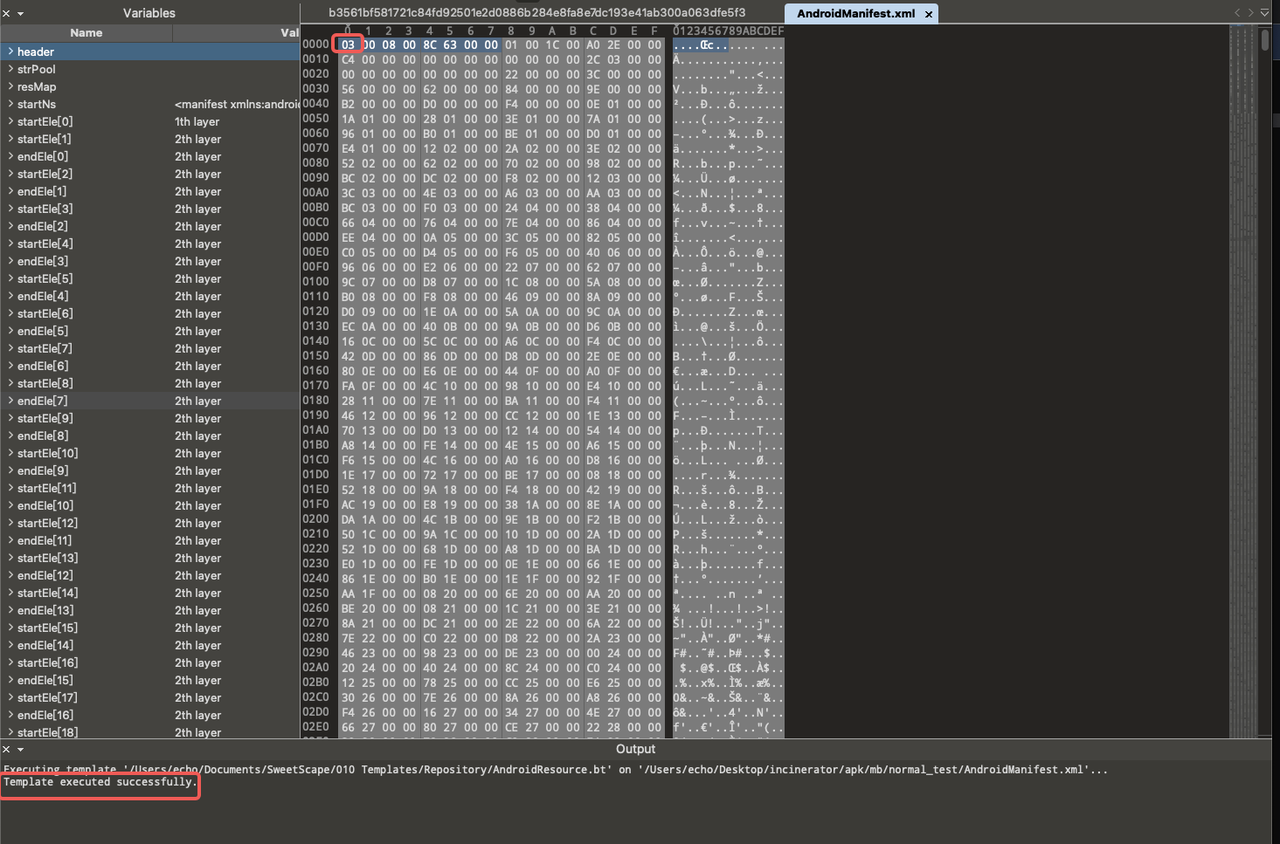
We manually corrected the first byte to 0x03 for further analysis. Upon attempting to parse it again with the AndroidResource template, we found that the analysis still failed. It only displayed the string pool without parsing out the main XML node.
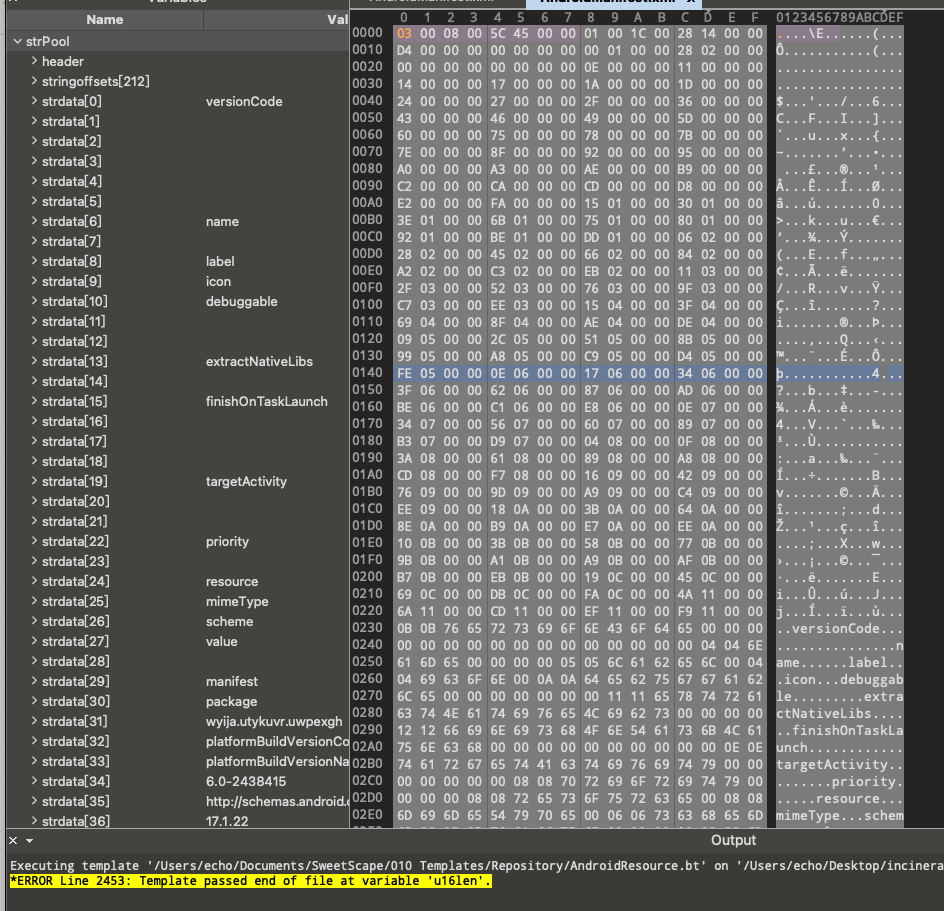
We expanded the data in stringoffsets for examination. Starting from the 131st stringoffset, the data showed significant anomalies, far exceeding the entire length of the file, clearly indicating an error. Upon further analysis of the stringPool header information, we calculated that the actual number of strings is 131.
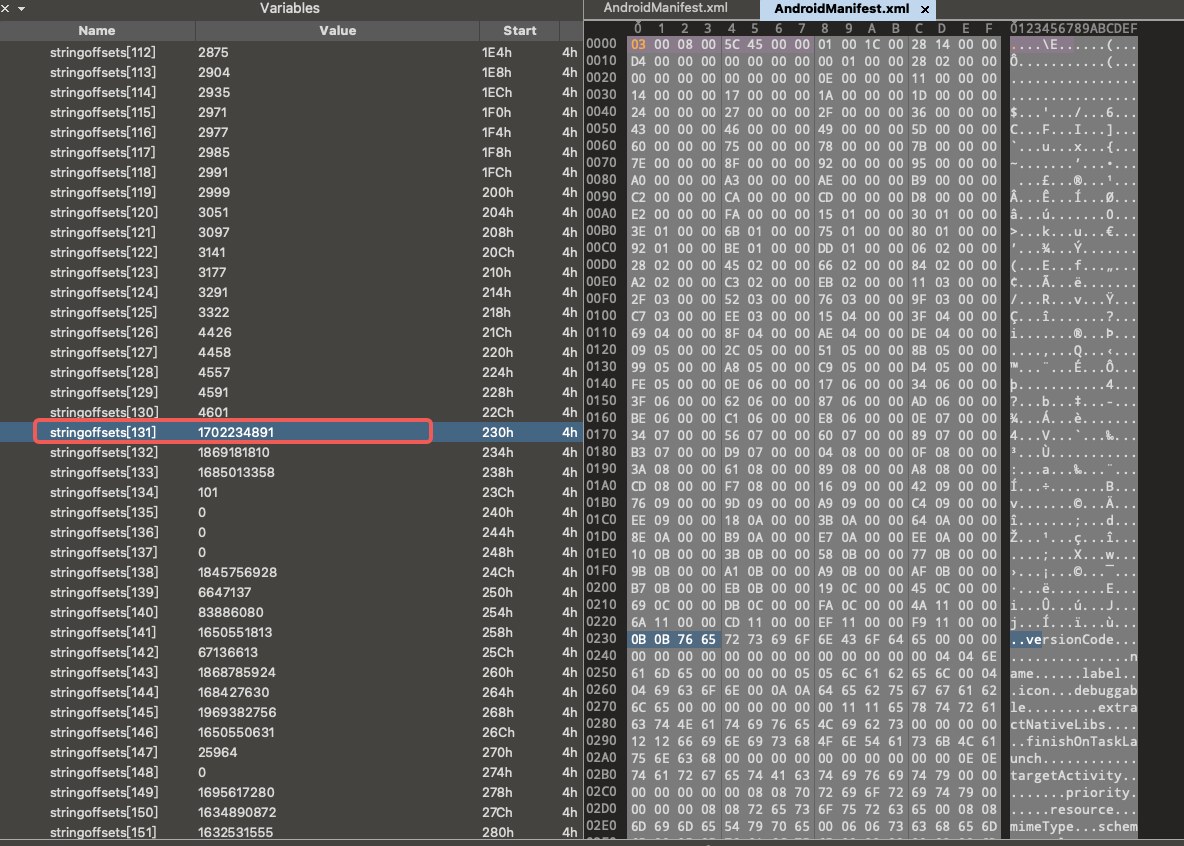
In the stringoffsets field of sample b356, starting from the 131st entry, the data clearly shows anomalies: these values far exceed the actual length of the entire file. This inconsistency clearly points to an error and suggests that the number of entries recorded in stringoffsets is likely inaccurate.
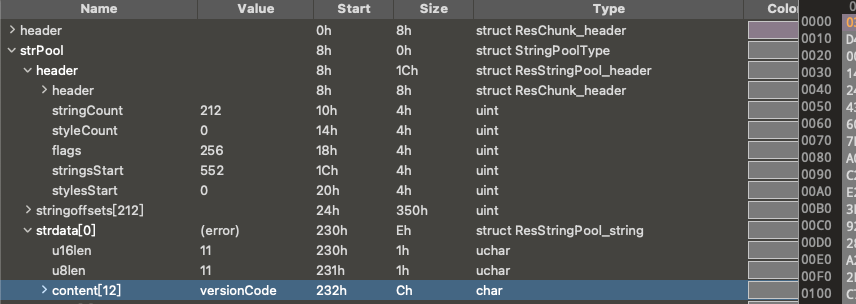
Upon conducting a deep analysis of the stringpool structure in sample b356, we first confirmed that strdata[0], i.e., the first string in stringpool, was correctly parsed. This is crucial because it verifies that our starting position for parsing (0x230, which is 560 in decimal) is accurate.
The stringsStart field indicates that the starting position of the stringpool is 552 bytes from the beginning of the file header. Since there are typically 8 bytes used to store meta-information about the stringpool (such as length or other flags), 552 + 8 equals precisely 560.
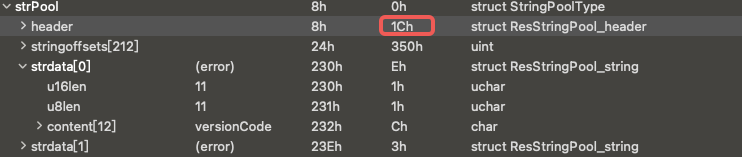
This naturally raises a question: What exactly does the content of these 552 bytes comprise? We know that the strPoolheader itself takes up 28 bytes (or 0x1C). If we subtract these 28 bytes from the 552, what are the remaining 524 bytes used for?
The remaining 524 bytes are very likely used to store stringoffsets. Each stringoffset typically takes up 4 bytes, so 524/4 equals precisely 131. This aligns with the number of stringoffsets that we previously calculated manually.
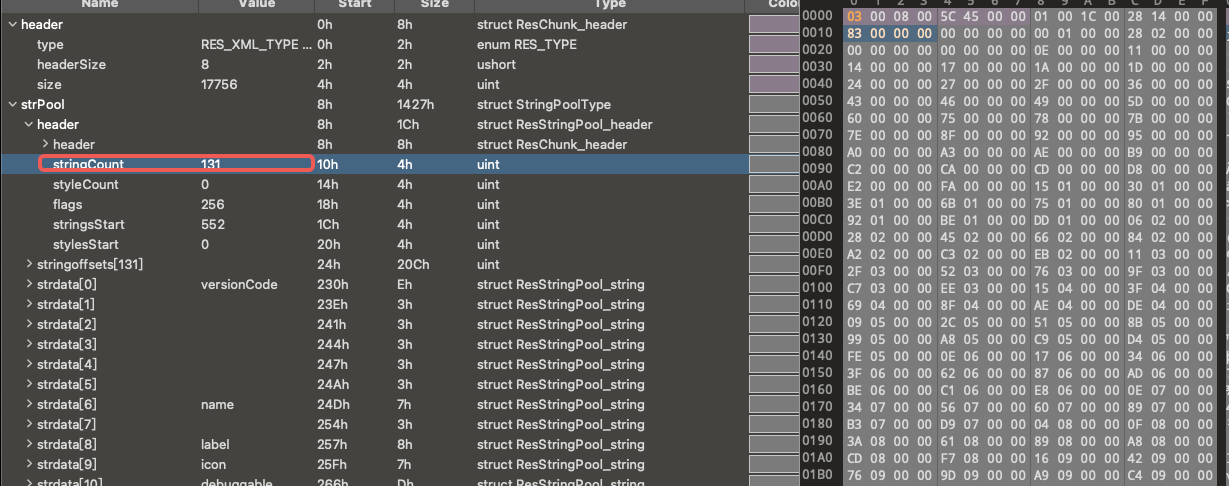
In our previous in-depth analysis, we inferred that the actual number of stringoffsets is 131, which is inconsistent with the incorrectly identified number in sample b356. To more accurately parse this sample, we decided to correct the stringCount field.
Why Can the Android System Parse It Correctly?
As shown in the source code for system parsing stringPoolsize above, stringPoolsize is computed. Therefore, the modifications to stringPoolsize in sample b356 effectively break many static analysis tools that read stringPoolsize from the file. However, the Android system can still obtain the correct stringPoolSize through calculations during parsing.
Modification Suggestions
Suggested Modification for Static Analysis Tools: Follow the Android system's approach, where stringPoolSize is computed rather than parsed from the file.
- Manual Adjustment: First, find the
stringCountfield in thestringPoolheader of sample b356 and change its value to 131. - Reparse: After completing the modification, we use
010 Editoralong with theAndroidResourcetemplate to parse the sample again.
After the modification, we find that the main XML nodes have been successfully parsed. This means that our manual adjustment is effective, and we can now see more internal details of the sample.
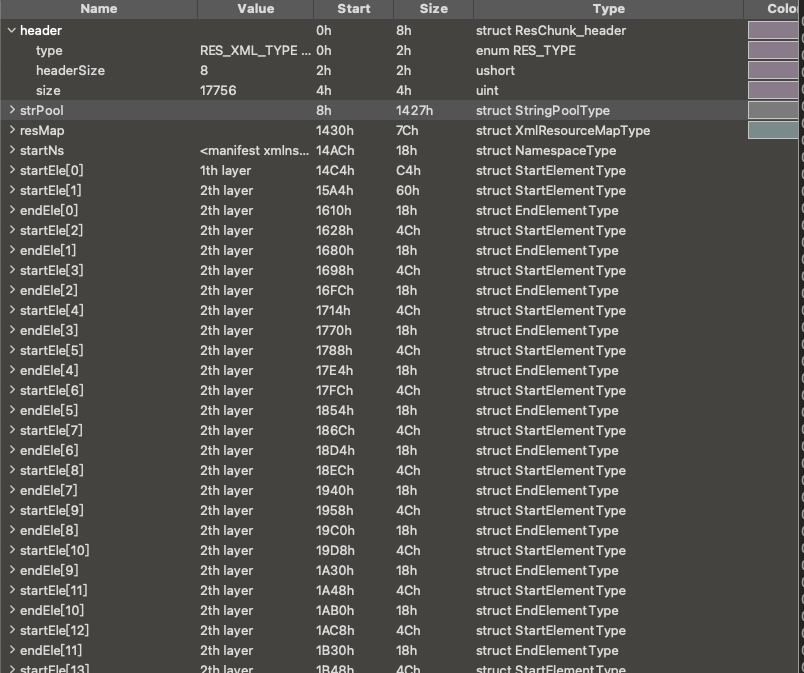
Despite manually fixing the stringCount and successfully parsing the main nodes of AndroidManifest.xml using 010 Editor, dedicated static analysis tools still encounter errors. The specific error occurs at the 0x1588 byte position in the binary file.
Insert obfuscated data at the end of the XML node
Analysis of Anomalous Data
We manually modify the stringCount to 131 in order to continue the analysis.
Upon reloading the modified file with 010 Editor, the result is as shown in the following figure:
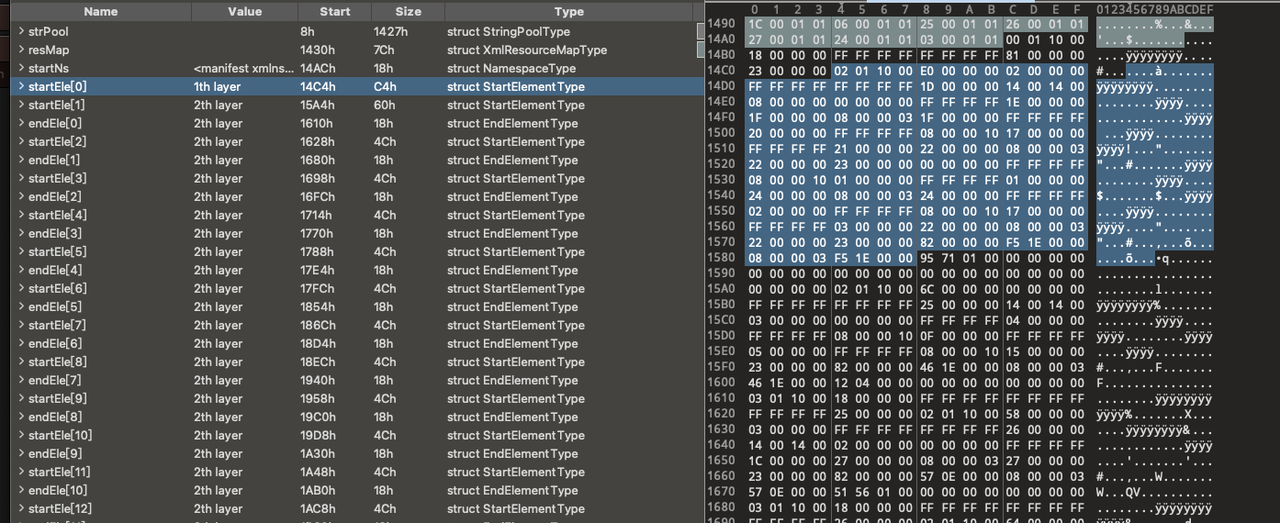
010 Editor has no issues during parsing, but when using static analysis tools, unexpected data is encountered at byte 0x1588.
At byte position 0x1587, the first XML element has already ended. Static analysis tools expect byte 0x1588 to serve as the starting point for the next ResChunk_header for analysis. However, an exception occurs when attempting to parse the size field at byte 0x158A. According to the constraints of the ResChunk_header structure, this size value should be at least greater than 8, but the actual data does not meet this condition.
It seems that sample b356 has inserted some non-standard or obfuscated data at byte 0x1588, causing the static analysis tool to fail in its analysis.
Based on the parsing results from 010 Editor, we know that the headersize field of 'startEle' has been modified, allowing for the addition of obfuscated content after the element ends.
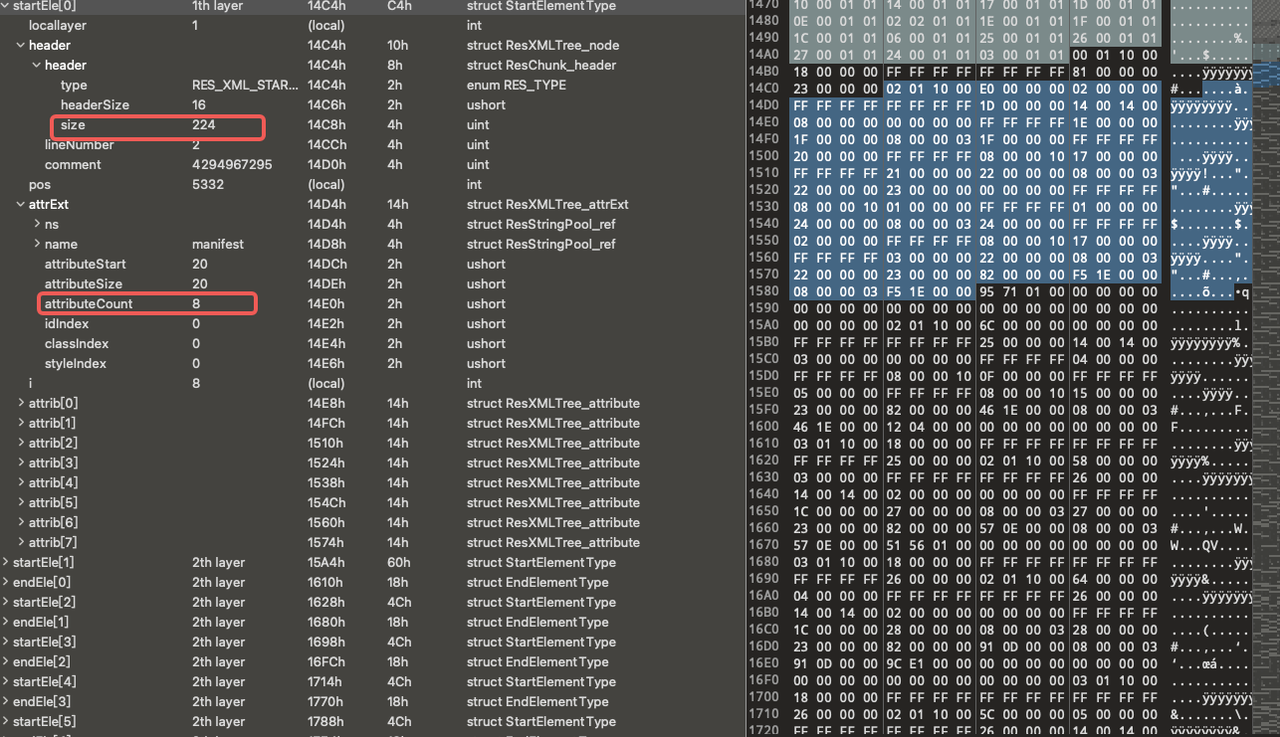
After parsing the attribute field, if the parsing is not yet complete or an exception is encountered, the tool should automatically skip to the position defined by elementStart + size and begin parsing the next element from there. The purpose of doing this is to bypass any potential interference or erroneous data.
Why Android Systems Can Parse?
As shown in the Android system source code below, each attribute's data is calculated through the position of attributeExt, the start of attributeExt, and the size of attributeExt. The start and size of attributeExt are read from the bytes. Therefore, as long as the start of attributeExt is correct, it ensures that the correct attributeData can be obtained.
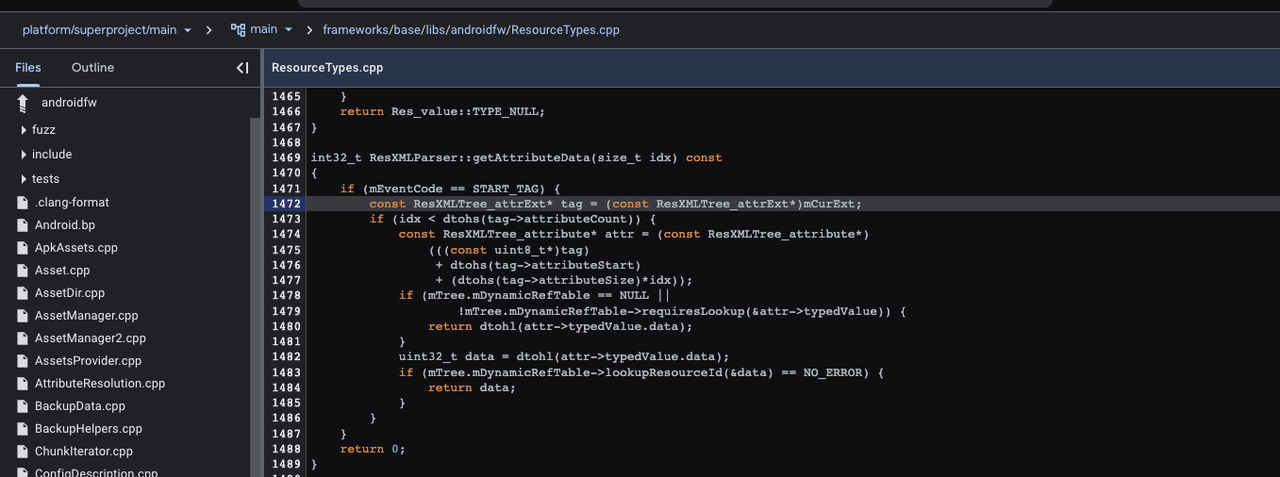
The attributeExt is located based on the size and position specified in the header of the current XML node. Specifically, every time a new node is parsed, the position is calculated by adding the size value read from the header of the current node to the current node's position.
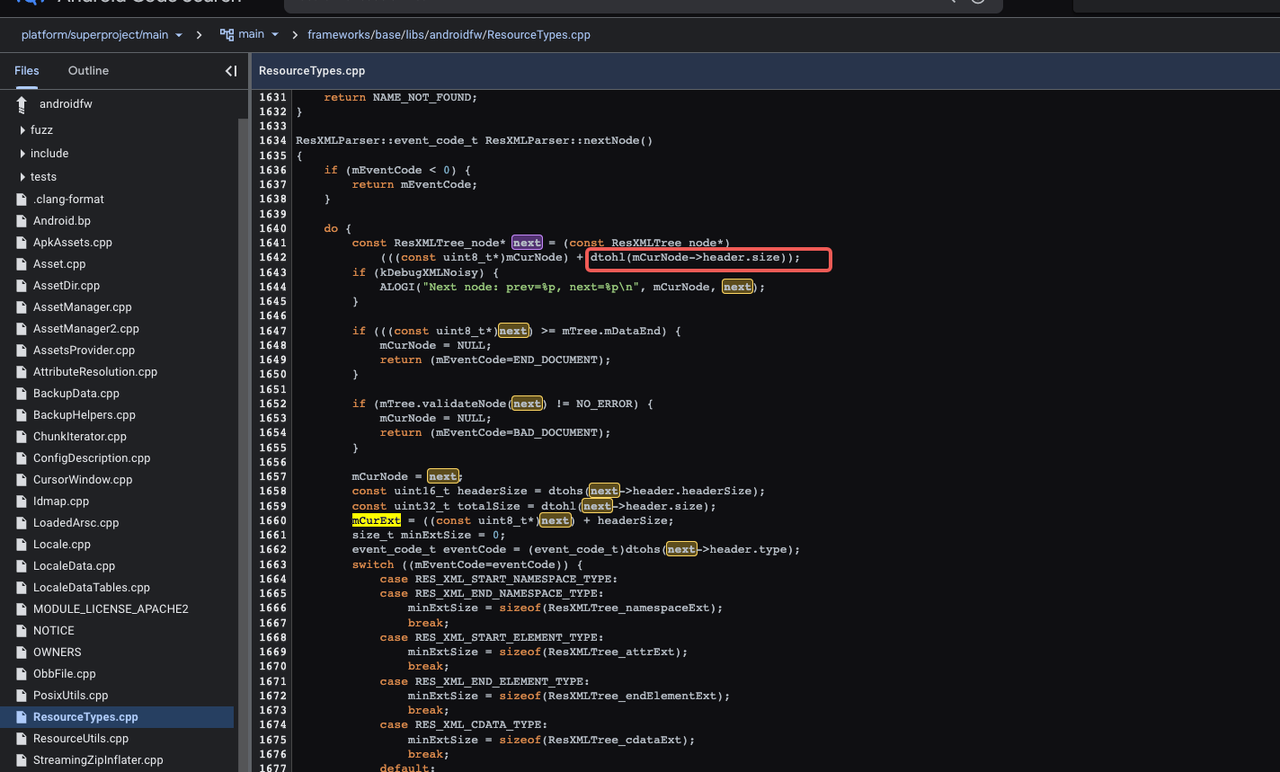
In the case of the sample b356, the position of startEle[1] is calculated as the position of startEle[0] plus startEle[0].header->size. Therefore, while sample b356 inserts disruptive data after the end of startEle[0] in the original APK, it also modifies the length of startEle[0].header->size, enabling the system to parse it correctly.
In other words, the system continues to parse correctly because it moves to the next node based on the modified 'size' value in the header, effectively bypassing the disruptive or obfuscating data that was inserted.
Modification Suggestions
Suggested Modification for Static Analysis Tools: Consider following the parsing method used by the Android system, where the starting position of each XML node is calculated based on the starting position of the previous node plus the length of the previous node.
Summary
The "b356" sample showcases obfuscation and concealment techniques at multiple layers and dimensions, with a clear aim: to resist and disrupt the capabilities of standard decompression tools and static analysis decoding.
The primary reason why b356 can successfully obfuscate is the difference in some of the finer details between the Android system's parsing process and the commonly used static analysis tools in the market.
In this sample, there are only three modification points, but other samples may have additional points. We will continue to analyze these in our next blog post.
However, a reactive approach of patching individual issues is certainly not the ideal solution. Instead, a more systematic approach should be taken to align the static analysis techniques with the Android system's parsing process. For example, converting the system source code parsing method into one compatible with static analysis tools, which would require a collective effort from the community.
Special Thanks:
Thank you to ReBensk for your ongoing support. We're grateful for your quiet use of incinerator.cloud and your tireless contributions of many unique samples. We greatly appreciate your willingness to publicly share all your sample analysis reports from your incinerator.cloud account with the community. Thanks to 0x6rss for your assistance in both technical and other matters. You're an excellent brother who has taught us many new techniques. Our team hasn't worked in the malware analysis field for many years, and you've helped us learn a lot more. Thank you. Thanks to MalwareBug for submitting many samples and issues to us. Your ongoing support for the development of incinerator is invaluable, and I look forward to each of your articles! Thanks to JoeSecurity. If it weren't for you identifying the issue with Zip types, we wouldn't have been inspired to analyze related technologies. We also hope to gain access to your Sandbox services since I've never successfully registered. Thank you to Fernando Sánchez for sharing your technical insights. We are very grateful!